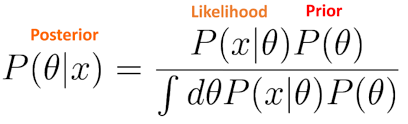BDAI LMS, 런칭 3개월 만에 가입자 3,000명 돌파! 학회원들의 목적지는 어디일까요?
안녕하세요, 오늘은 BDAI LMS의 가파른 성장과 저희가 만들어가고 있는 새로운 연결에 대해 이야기해 보려 합니다.
이번 12기부터 새롭게 선보인 LMS(Learning Management System)는 학회원들의 성장을 밀착 지원하기 위해 탄생한 내부 시스템입니다. 지난 4년 동안 학회를 이끌어온 노하우를 집약해 운영진과 함께 직접 기획하고 개발하며 지금도 끊임없이 발전시켜 나가고 있습니다.
감사하게도 지난 3월 첫 런칭 후 단 3개월 만에 3,000명 이상이 회원가입을 해주셨습니다. 특히 내부 학회원뿐만 아니라, 외부의 많은 비학회원분들까지 적극적으로 참여해 주시고 계셔 더욱 뜻깊습니다.
수많은 비학회원분들의 발길이 머무는 곳, 바로 '공모전/해커톤' 페이지입니다.
현재 BDAI는 여러 스타트업과 손잡고 그들이 직면한 실무 문제를 해결하는 공모전과 해커톤을 활발히 개최하고 있습니다. 이번에는 데이톤 & 슈퍼브에이아이(Superb AI)와 함께 뜻깊은 해커톤을 진행 중입니다.
기업은 그동안 풀지 못했던 과제에 대해 20대 청년들의 톡톡 튀는 아이디어와 인사이트를 얻을 수 있고, 나아가 자사에 적합한 우수 인재를 발굴할 수도 있습니다. BDAI는 이러한 산학협력 프로젝트를 기업 측에 별도의 비용을 받지 않고 진행하고 있어, 현재 정말 많은 기업에서 문의를 주시고 있습니다.
저희 BDAI의 미션에 깊이 공감해 주시고 흔쾌히 함께해 주시는 모든 파트너 기업 관계자분들께 이 자리를 빌려 다시 한번 진심으로 감사의 말씀을 전합니다.
앞으로도 미래의 인재와 기업을 잇는 튼튼한 다리가 되겠습니다.
단순한 교육을 넘어 청년 인재와 기업을 연결하며, 사회 전반에 선한 영향력을 더욱 확대해 나가는 BDAI가 되겠습니다.
기업이 가진 문제를 청년들의 열정과 아이디어로 함께 풀어가고 싶으신 담당자분들은 언제든 아래 메일로 편하게 연락해 주시면 상세히 안내해 드리겠습니다.
공모전/해커톤 및 제휴 문의: official.biz.bda@gmail.com
조만간 또 다른 새롭고 흥미로운 이야기로 찾아뵙겠습니다.
감사합니다!
안녕하세요, 오늘은 BDAI LMS의 가파른 성장과 저희가 만들어가고 있는 새로운 연결에 대해 이야기해 보려 합니다.
이번 12기부터 새롭게 선보인 LMS(Learning Management System)는 학회원들의 성장을 밀착 지원하기 위해 탄생한 내부 시스템입니다. 지난 4년 동안 학회를 이끌어온 노하우를 집약해 운영진과 함께 직접 기획하고 개발하며 지금도 끊임없이 발전시켜 나가고 있습니다.
감사하게도 지난 3월 첫 런칭 후 단 3개월 만에 3,000명 이상이 회원가입을 해주셨습니다. 특히 내부 학회원뿐만 아니라, 외부의 많은 비학회원분들까지 적극적으로 참여해 주시고 계셔 더욱 뜻깊습니다.
수많은 비학회원분들의 발길이 머무는 곳, 바로 '공모전/해커톤' 페이지입니다.
현재 BDAI는 여러 스타트업과 손잡고 그들이 직면한 실무 문제를 해결하는 공모전과 해커톤을 활발히 개최하고 있습니다. 이번에는 데이톤 & 슈퍼브에이아이(Superb AI)와 함께 뜻깊은 해커톤을 진행 중입니다.
기업은 그동안 풀지 못했던 과제에 대해 20대 청년들의 톡톡 튀는 아이디어와 인사이트를 얻을 수 있고, 나아가 자사에 적합한 우수 인재를 발굴할 수도 있습니다. BDAI는 이러한 산학협력 프로젝트를 기업 측에 별도의 비용을 받지 않고 진행하고 있어, 현재 정말 많은 기업에서 문의를 주시고 있습니다.
저희 BDAI의 미션에 깊이 공감해 주시고 흔쾌히 함께해 주시는 모든 파트너 기업 관계자분들께 이 자리를 빌려 다시 한번 진심으로 감사의 말씀을 전합니다.
앞으로도 미래의 인재와 기업을 잇는 튼튼한 다리가 되겠습니다.
단순한 교육을 넘어 청년 인재와 기업을 연결하며, 사회 전반에 선한 영향력을 더욱 확대해 나가는 BDAI가 되겠습니다.
기업이 가진 문제를 청년들의 열정과 아이디어로 함께 풀어가고 싶으신 담당자분들은 언제든 아래 메일로 편하게 연락해 주시면 상세히 안내해 드리겠습니다.
공모전/해커톤 및 제휴 문의: official.biz.bda@gmail.com
조만간 또 다른 새롭고 흥미로운 이야기로 찾아뵙겠습니다.
감사합니다!